 轻松搞定:Qwen3-32B 生产环境离线部署全流程
轻松搞定:Qwen3-32B 生产环境离线部署全流程
作者:鱼仔
博客首页: codeease.top (opens new window)
公众号:神秘的鱼仔
# 背景
前段时间Qwen3发布,并且在效果上十分不错,刚好我目前的本职工作都和AI有关,也有一定的显卡资源,于是就做了Qwen3 原版32B模型的部署和使用,目前已经发布到生产环境供AI应用使用,本篇博客给出Qwen3生产环境完全离线部署的攻略。
# 部署及使用概况
我使用的生产环境操作环境为CentOS7.9,显卡配置为8张A10显卡,每张显卡显存为32G,使用vllm进行生产环境部署,使用中占用总显存达到160G左右
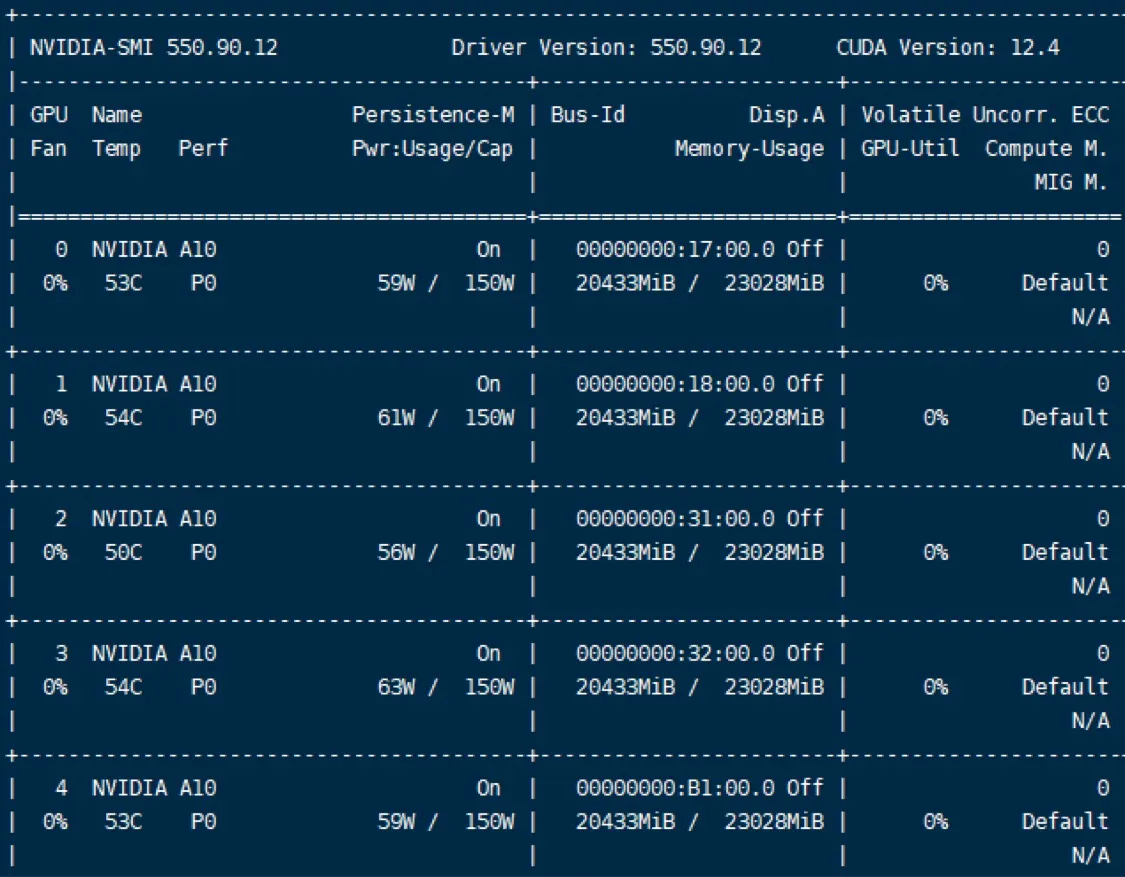
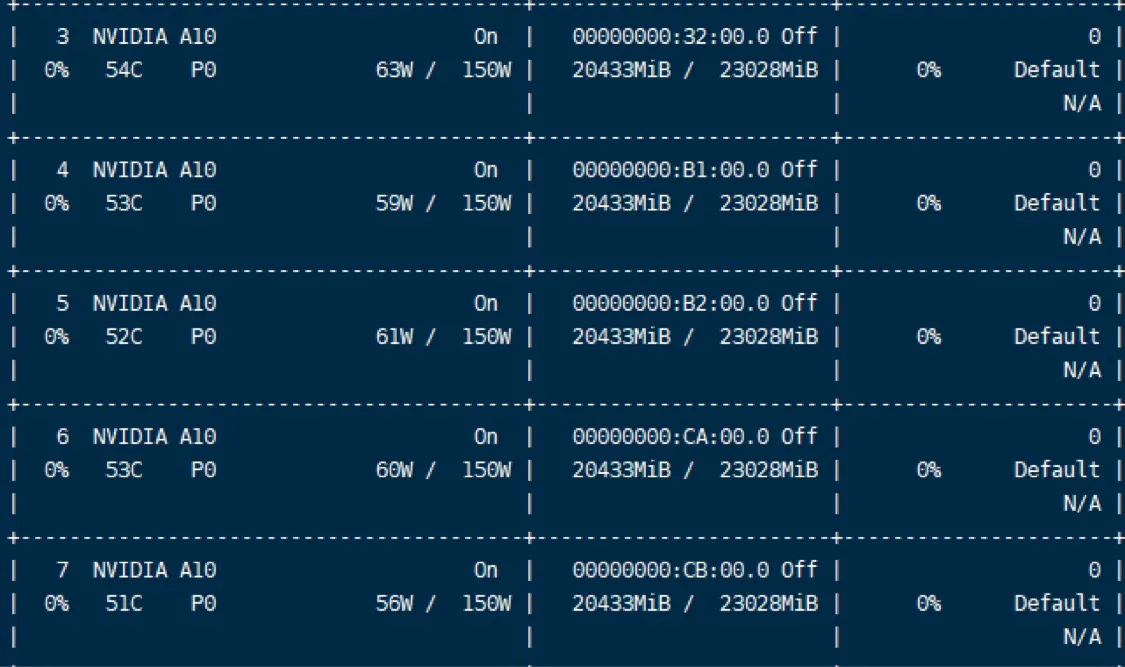
平均推理速度为36tokens每秒,体验感觉还是比较快的。

# Qwen3相关地址
模型下载地址:https://huggingface.co/Qwen/Qwen3-32B (opens new window)
github地址:https://github.com/QwenLM/Qwen3 (opens new window)
# 版本要求
官方文档推荐SGLang或者vllm进行生产环境的模型部署,我用vllm比较多,因此使用vllm进行生产部署
Qwen3对transformers以及vllm的版本要求较高,我用跑Qwen2.5的虚拟环境去运行Qwen3无法成功。以下是具体的版本要求:
vllm:大于等于0.8.5
transformers:大于等于4.51.0
gcc/g++:需要支持c++17,我用的版本是g++11.3.0
python:建议python 3.9以上,我用的版本是3.9.19
# 安装方案
# 包准备
G++11相关:gmp-6.2.1.tar.xz、mpfr-4.2.0.tar.xz、mpc-1.3.1.tar.gz、isl-0.24.tar.bz2、gcc-11.3.0.tar.gz
python3.9.19:python3.9.19.tar.gz
# G++11安装
下面的这几步操作需要在root账号下执行
安装gmp
tar -xvf gmp-6.2.1.tar.xz
cd gmp-6.2.1
./configure --prefix=/usr/local/gmp-6.2.1
make -j8
make install -j8
tar -xvf mpfr-4.2.0.tar.xz
2
3
4
5
6
安装mpfr
cd mpfr-4.2.0
./configure --prefix=/usr/local/mpfr-4.2.0 --with-gmp-include=/usr/local/gmp-6.2.1/include --with-gmp-lib=/usr/local/gmp-6.2.1/lib
make -j8
make install -j8
2
3
4
安装mpc
tar -xvf mpc-1.3.1.tar.gz
cd mpc-1.3.1
./configure --prefix=/usr/local/mpc-1.3.1 --with-gmp-include=/usr/local/gmp-6.2.1/include --with-gmp-lib=/usr/local/gmp-6.2.1/lib --with-mpfr-include=/usr/local/mpfr-4.2.0/include --with-mpfr-lib=/usr/local/mpfr-4.2.0/lib
make -j8
make install -j8
2
3
4
5
安装isl
tar -xvf isl-0.24.tar.bz2
cd isl-0.24
./configure --prefix=/usr/local/isl-0.24 --with-gmp-prefix=/usr/local/gmp-6.2.1
make -j8
make install -j8
2
3
4
5
环境变量配置
vi ~/.bashrc
// 在最后一行加上
export LD_LIBRARY_PATH=/usr/local/gmp-6.2.1/lib:/usr/local/mpfr-4.2.0/lib:/usr/local/mpc-1.3.1/lib:/usr/local/isl-0.24/lib:$LD_LIBRARY_PATH
// 保存后执行
source ~/.bashrc
2
3
4
5
6
7
安装gcc11,这一步需要的时间会比较久
mkdir -p /usr/local/gcc-11.3.0
tar -xvf gcc-11.3.0.tar.gz
cd gcc-11.3.0
./configure --prefix=/usr/local/gcc-11.3.0 --with-gmp=/usr/local/gmp-6.2.1/ --with-mpfr=/usr/local/mpfr-4.2.0 --with-mpc=/usr/local/mpc-1.3.1 --with-isl=/usr/local/isl-0.24 --disable-multilib
make -j8
make install -j8
2
3
4
5
6
配置环境变量
vi ~/.bashrc
// 在最后一行加上
export PATH=/usr/local/gcc-11.3.0/bin:$PATH
source ~/.bashrc
2
3
4
5
6
重新创建软链接,因为CentOS7.9默认使用的是gcc4.8.5
mv /usr/lib64/libstdc++.so.6 /usr/lib64/libstdc++.so.6.bak
ln -s /usr/local/gcc-11.3.0/lib64/libstdc++.so.6.0.29 /usr/lib/libstdc++.so.6
mv /usr/bin/gcc /usr/bin/gcc-4.8.5
mv /usr/bin/g++ /usr/bin/g++-4.8.5
ln -s /usr/local/gcc-11.3.0/bin/gcc /usr/bin/gcc
ln -s /usr/local/gcc-11.3.0/bin/g++ /usr/bin/g++
2
3
4
5
6
现在切换回到正常的非root账号
配置环境变量
vi ~/.bashrc
// 在最后加上
export LD_LIBRARY_PATH=/usr/local/gmp-6.2.1/lib:/usr/local/mpfr-4.2.0/lib:/usr/local/mpc-1.3.1/lib:/usr/local/isl-0.24/lib:/usr/local/gcc-11.3.0/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/gcc-11.3.0/bin:$PATH
// 刷新环境变量
source ~/.bashrc
2
3
4
5
6
7
8
最后执行g++ -v 命令验证是否安装成功

# Python3.9安装
因为现在很多模型要求openssl达到1.1.1以上版本,因此先安装openssl 1.1.1。
openssl1.1.1s 下载地址:https://openssl-library.org/source/old/1.1.1/index.html (opens new window)
安装:
tar -zxvf openssl-1.1.1s.tar.gz
cd openssl-1.1.1s
./config --prefix=/home/ai/bin/openssl
make
make install
2
3
4
5
下载Python-3.9.19.tgz,下载地址:https://python.org/ftp/python/3.9.19 (opens new window)
下载完成后将文件放到Linux服务器上
tar -xvf Python-3.9.19.tgz
cd Python-3.9.19
make clean
export LD_LIBRARY_PATH=/home/ai/bin/openssl/lib:$LD_LIBRARY_PATH
./configure --prefix=/home/ai/bin/python3.9 --with-openssl=/home/ai/bin/openssl/lib
make
make altinstall
2
3
4
5
6
7
配置环境变量
vi ~/.bashrc
在最后一行加上:
export PATH=/home/ai/bin/python3.9/bin:$PATH
export LD_LIBRARY_PATH=/home/ai/bin/openssl/lib:$LD_LIBRARY_PATH
2
刷新环境变量
source ~/.bashrc
验证:
python3.9 --version
输出版本号即为成功
验证ssl
python3.9 -c "import ssl; print(ssl.OPENSSL_VERSION)"
输出1.1.1版本即为成功。
# 虚拟环境构建
使用Python的虚拟环境对各个环境进行隔离,也可以直接把测试环境的这个虚拟环境直接搬到生产环境去,很方便。
python3.9 -m venv qwen3_venv
source qwen3_venv/bin/activate
2
现在你就进入到这个虚拟环境中了。
# 依赖下载
主要下载两个重要的依赖:
pip install transformers==4.51.3
pip install vllm==0.8.5
2
如果有其他需要下载的依赖按需下载即可。
# 执行启动命令
通过vllm的命令行即可启动大模型,注意生产环境上可以把启动命令和停止命令做成脚本
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 nohup python -m vllm.entrypoints.openai.api_server --model=Qwen3-32B --max-model-len=32000 --served-model-name=qwen3_32b --device=cuda --port=10100 --host=0.0.0.0 --tensor-parallel-size=8 --gpu-memory-utilization=0.8 --dtype=auto --trust-remote-code >> qwen3.log &
当日志中出现下面这些内容的时候,就说明大模型成功启动了
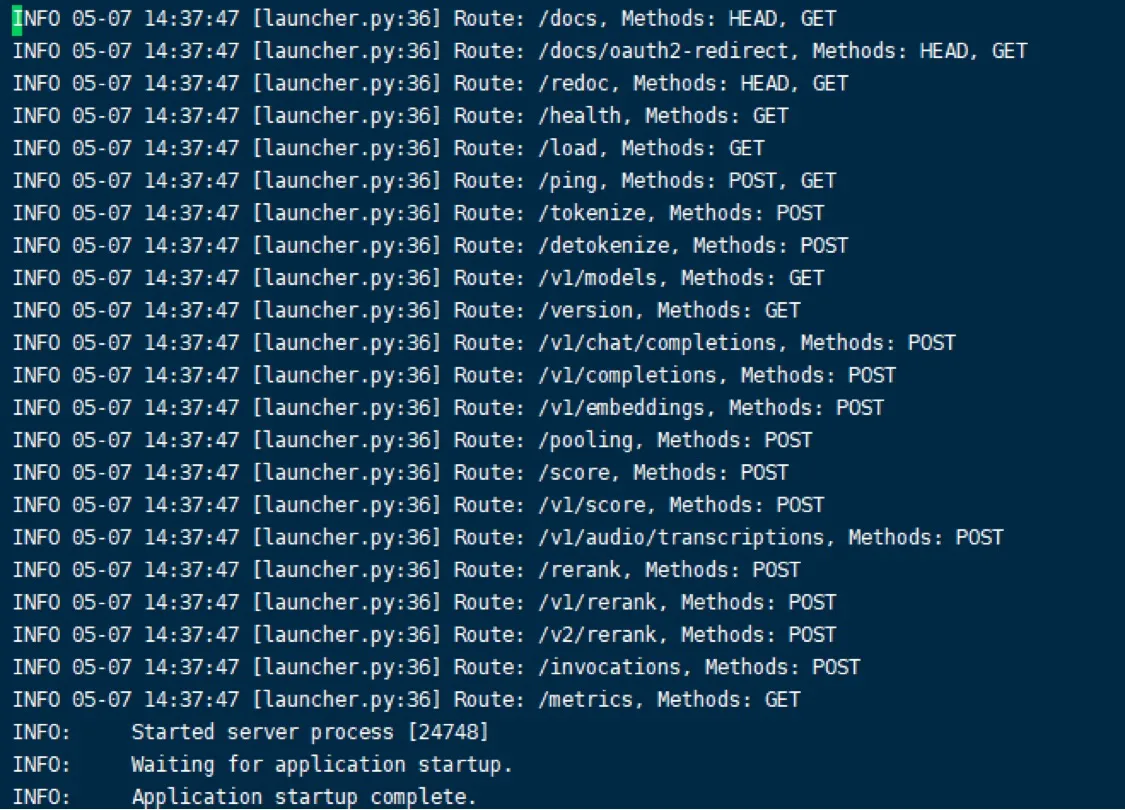
可以用标准的OpenAPI格式的接口直接调用大模型
# 模型的选择
Qwen3开源了多种规格的模型,但是原版模型需要的硬件资源是比较多的,因此可以尝试使用量化版本的模型,比如Qwen3-32B-AWQ,虽然降低了一些性能,但是只需要上面的两张卡就可以完成部署。最终的选择还是看大家自己的硬件资源和应用场景了。