 ClickHoust搭建文档
ClickHoust搭建文档
作者:鱼仔
博客首页: codeease.top (opens new window)
公众号:神秘的鱼仔
# 必备内容
下载地址
https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/ (opens new window)
我下载的是22.2.2.1-2版本

# 单机版
1、使用rpm命令进行安装**(root账号)**
rpm -ivh *.rpm
遇到输入密码的场景直接回车跳过。
2、通过下面的命令查看clickhouse的安装情况
rpm -qa|grep clickhouse
3、修改配置文件**(root账号)**
sudo vim /etc/clickhouse-server/config.xml
4、增加listen_host配置
<listen_host>::</listen_host>
5、启动clickhouse (root账号)
systemctl start clickhouse-server
6、查看clickhouse启动状态
systemctl status clickhouse-server
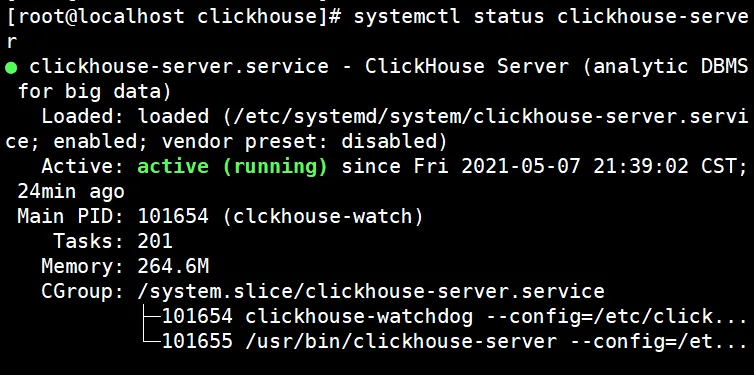
出现active表示启动成功。
7、执行clickhouse客户端
clickhouse-client -m
# 集群版
集群版的ClickHouse依赖Zookeeper集群,所以首先需要安装Zookeeper
# Zookeeper集群安装步骤
1、下载Zookeeper
本次部署通过离线部署,先下载tar包 http://archive.apache.org/dist/zookeeper/ (opens new window) 下载 apache-zookeeper-3.6.0-bin.tar.gz
2、将Zookeeper的tar包放到指定的目录下,我放到/usr/local下,执行解压缩命令(三台机器都执行)
cd /usr/local
tar -xvf apache-zookeeper-3.6.0-bin.tar.gz
mv apache-zookeeper-3.6.0-bin zookeeper
cd zookeeper/
mkdir data
mkdir logs
2
3
4
5
6
3、配置文件修改(三台机器都执行)
cd conf/
vim zoo.cfg
2
配置如下
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
clientPort=2181
server.1=192.168.78.128:2888:3888
server.2=192.168.78.130:2888:3888
server.3=192.168.78.131:2888:3888
2
3
4
5
6
7
8
9
4、配置节点标识(三台机器都执行)
按配置文件中的服务地址,在各自的服务器上将身份标识写入
echo "1" > /usr/local/zookeeper/data/myid
echo "2" > /usr/local/zookeeper/data/myid
echo "3" > /usr/local/zookeeper/data/myid
5、启动zookeeper服务(三台机器都执行)
cd /usr/local/zookeeper/
./bin/zkServer.sh start
2
如果提示STARTED 即表示启动成功

# ClickHouse集群安装
首先在三台机器上均按单机版安装ClickHouse,单机版安装方式见上图
接着配置进入新建一个配置文件 metrika.xml
cd /etc/clickhouse-server/
vim metrika.xml
2
配置文件填写方式如下图所示,其中Clickhouse和Zookeeper的地址按实际地址填写
<?xml version="1.0"?>
<yandex>
<clickhouse_remote_servers>
<test_cluster1>
<shard>
<replica>
<host>192.168.78.128</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>192.168.78.130</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>192.168.78.131</host>
<port>9000</port>
</replica>
</shard>
</test_cluster1>
</clickhouse_remote_servers>
<zookeeper-servers>
<node index="1">
<host>192.168.78.128</host>
<port>2181</port>
</node>
<node index="2">
<host>192.168.78.130</host>
<port>2181</port>
</node>
<node index="3">
<host>192.168.78.131</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
接着修改ClickHouse的config.xml配置文件
vim config.xml
在 <clickhouse> 的节点下增加下面的配置文件
<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/metrika.xml</include_from>
<remote_servers incl="clickhouse_remote_servers" />
2
3
另外原来的配置文件中还有 <remote_servers>节点,需要将整个节点的内容删除。
最后启动每一台机器的ClickHouse
systemctl status clickhouse-server
启动完成后进入任意一台机器的客户端页面
clickhouse-client -m
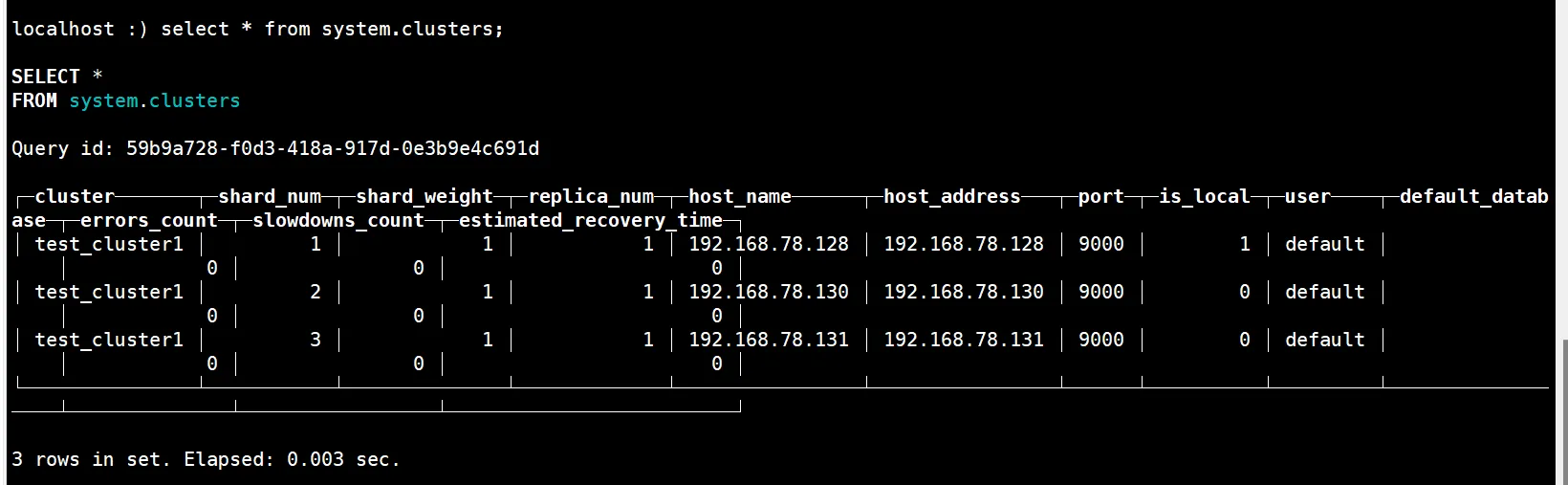
执行SQL语句
select * from system.clusters;
如果正常出现集群信息说明安装成功
create table events_local on cluster test_cluster1 (
ID String,
EventType UInt8,
URL String,
EventTime DateTime
) ENGINE = ReplicatedMergeTree('/ch/tables/test/events_local/{shard}', '{replica}')
PARTITION BY toStartOfDay(EventTime)
ORDER BY (EventTime,EventType)
SETTINGS index_granularity = 8192;
2
3
4
5
6
7
8
9